Clean • Professional
Spring Data JDBC is a lightweight data-access framework from Spring that helps you work with relational databases in a simple, predictable, and SQL-friendly way.
It is designed for developers who want control and clarity, not ORM magic.
Spring Data JDBC is part of the Spring Data family that allows you to:
👉 In simple words:
Spring Data JDBC = JDBC + Repository abstraction (No ORM)
Spring Data JDBC was introduced to solve issues caused by heavy ORM frameworks like JPA/Hibernate.
Spring Data JDBC follows Domain-Driven Design (DDD) principles.
Spring Data JDBC is designed to be simple, explicit, and predictable.
Below is a breakdown of its key features and what they actually mean in practice.
| Feature | Spring Data JDBC | Explanation |
|---|---|---|
| ORM | No | Not an ORM like JPA/Hibernate; no entity lifecycle or complex mapping. |
| Lazy Loading | No | All data is fetched immediately; no hidden database calls. |
| Persistence Context | No | No first-level cache; every operation directly hits the database. |
| Caching | No | No automatic caching; behavior remains predictable. |
| SQL Visibility | High | SQL execution is explicit and easy to trace. |
| CRUD Support | Yes | Built-in CRUD methods via CrudRepository. |
| Simplicity | Very High | Minimal features, easy to learn, easy to maintain. |
Controller
↓
Service
↓
Repository (SpringData JDBC)
↓
Database
Spring Data JDBC maps Java objects directly to database tables in a simple and predictable way.

Example Entity
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.Table;
@Table("users")// Maps this class to the "users" table
publicclassUser {
@Id// Primary key
private Long id;
private String name;
private String email;
// Getters and setters
public LonggetId() {return id; }
publicvoidsetId(Long id) {this.id = id; }
public StringgetName() {return name; }
publicvoidsetName(String name) {this.name = name; }
public StringgetEmail() {return email; }
publicvoidsetEmail(String email) {this.email = email; }
}
| Annotation | Purpose |
|---|---|
@Table | Maps the class to a specific database table |
@Id | Marks the primary key of the table |
@Column | Maps a field to a specific column (optional; defaults to field name) |
Key Points
Spring Data JDBC provides repository interfaces to simplify data access. The most common one is CrudRepository, which provides basic CRUD operations out-of-the-box.
Example Repository
import org.springframework.data.repository.CrudRepository;
publicinterfaceUserRepositoryextendsCrudRepository<User, Long> {
// No implementation needed
}
User → Entity typeLong → Type of primary key (@Id field)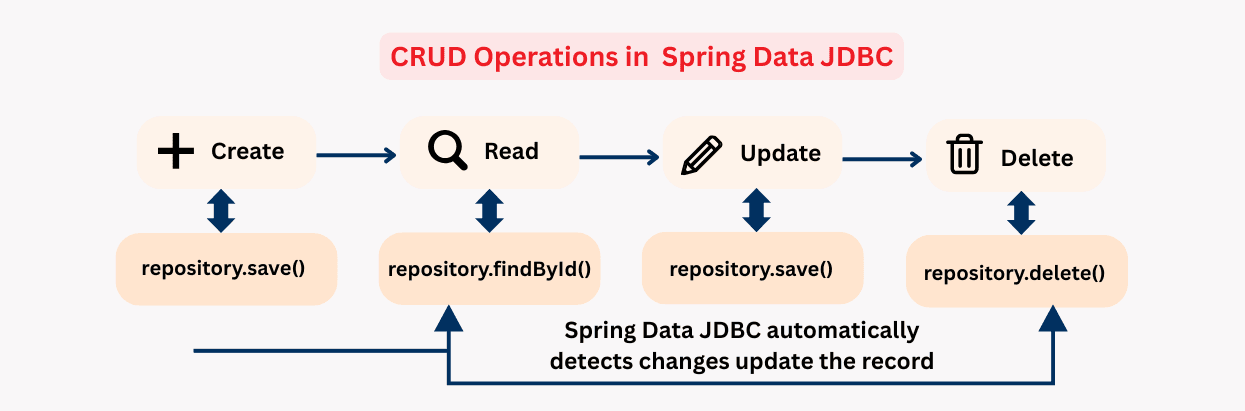
| Method | Description |
|---|---|
save() | Insert or update an entity |
findById(ID id) | Retrieve an entity by primary key |
findAll() | Retrieve all entities |
deleteById(ID id) | Delete entity by primary key |
Key Points
Useruser=newUser();
user.setName("Amit");
user.setEmail("[email protected]");
// Save entity
userRepository.save(user);
Key Points
@Id).// Fetch a single user by ID
Optional<User> user = userRepository.findById(1L);
// Fetch all users
Iterable<User> users = userRepository.findAll();
Key Points
Optional for single entity to handle null-safety.findAll() retrieves all records without proxies or hidden queries.// Fetch user by ID and update
Useruser= userRepository.findById(1L).get();
user.setName("Rahul");
userRepository.save(user);
Key Points
// Delete user by ID
userRepository.deleteById(1L);
Key Points
Explains how transactions work in Spring Data JDBC without persistence context confusion.
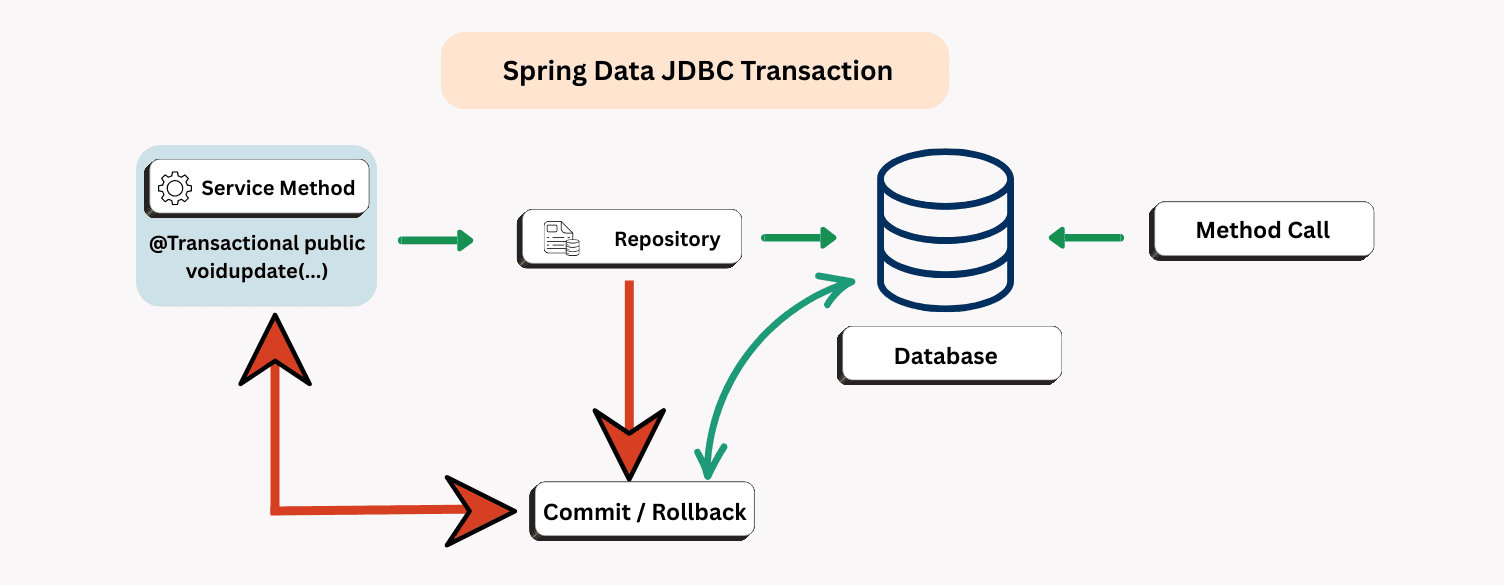
Spring Data JDBC integrates seamlessly with Spring’s @Transactional:
@Transactional
publicvoidcreateUser(User user) {
userRepository.save(user);
}
Key Points
Spring Data JDBC does not provide the following features:
Developers must explicitly manage queries, relationships, and updates.
Spring Data JDBC is ideal for scenarios that require simplicity, predictability, and control:
Avoid using it when your application requires:
Some frequent pitfalls when starting with Spring Data JDBC:
| Feature | Spring Data JDBC | Spring Data JPA | Difference / Notes |
|---|---|---|---|
| ORM | No | Yes | JDBC is simple and works directly with SQL; JPA is a full ORM, mapping objects to tables with complex features. |
| Lazy Loading | No | Yes | JDBC fetches all data immediately; JPA can defer loading related entities until needed. |
| Complexity | Low | High | JDBC is straightforward with minimal abstraction; JPA has entity states, persistence context, and caching, making it more complex. |
| SQL Control | High | Low | JDBC gives full control over SQL; JPA often generates SQL behind the scenes. |
| Performance Predictability | High | Medium | JDBC is predictable since queries execute exactly as written; JPA performance can vary due to caching, lazy loading, and automatic joins. |
Spring Data JDBC is a lightweight, straightforward framework for working with relational databases. It emphasizes simplicity, explicit SQL control, and predictable behavior, making it ideal for microservices and performance-critical applications. Unlike JPA, it avoids hidden complexity like lazy loading, automatic joins, or entity state tracking, allowing developers to write clean, maintainable, and easy-to-debug data access code.
